
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- RAC
- clean code
- heapq
- B*Tree인덱스구조
- index fast full scan
- 친절한SQL튜닝
- 데이터모델링
- join
- 파이썬
- SQLD
- database
- 로버트C마틴
- 결합인덱스구조
- SQLP
- 조인
- 클린코드
- 리트코드215
- B*Tree인덱스
- 클린 코드
- B*Tree
- 알고리즘
- db
- intellij
- table full scan
- Oracle
- 오라클튜닝
- 리눅스
- 오라클
- SQL튜닝의시작
- leetcode215
- Today
- Total
개발노트
오라클 Table Full Scan 과 Index Range Scan 의 차이 본문
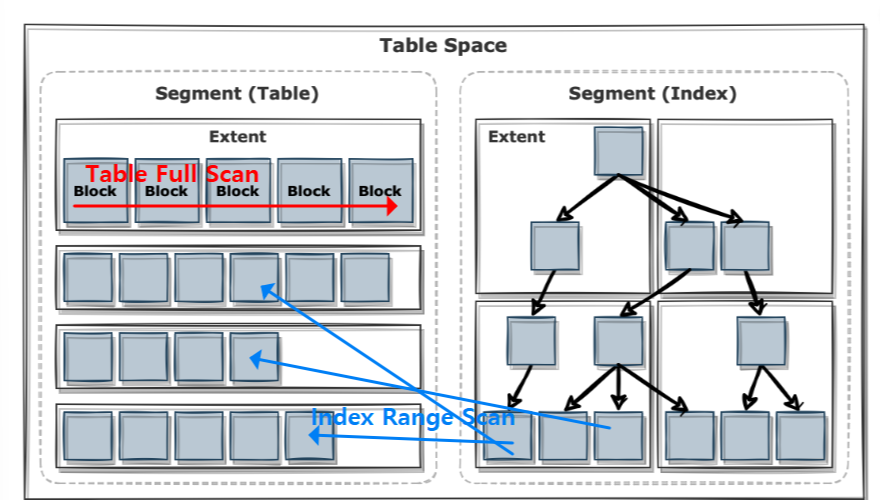
테이블에 저장된 데이터를 읽는 방식은 2가지다.
- 테이블 전체를 스캔해서 읽는 방식 : Table Full Scan
- 인덱스를 이용해서 읽는 방식 : Index Range Scan
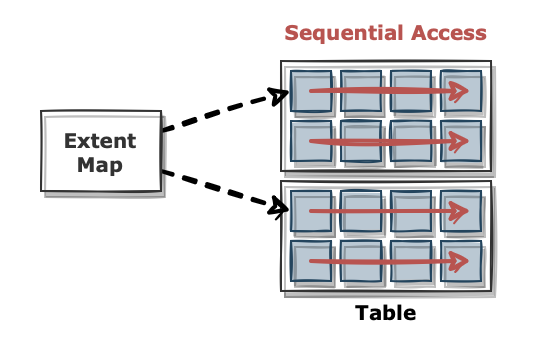
Table Full Scan 이란
시퀀셜 액세스와 Multiblock I/O 방식으로 디스크 블록을 읽는다.
한 블록에 속한 모든 레코드를 한 번에 읽어 들이고, 캐시에서 못 찾으면 '한 번의 수면(I/O Call)을 통해 인접한 수십~수백 개의 블록을 한꺼번에 I/O하는 메커니즘이다.
이 방식을 사용하는 SQL 은 스토리지 스캔 성능이 좋아지는 만큼 성능도 좋아진다.
그러나 시퀀셜 액세스와 multiblock i/o 가 아무리 좋아도 수십~수백 건의 "소량" 데이터를 찾을 때 수백만~수천만 건 데이터를 스캔하는 것은 비효율적이다. 그래서 큰 테이블에서 소량 데이터를 검색할 때는 반드시 인덱스를 이용해야 한다.
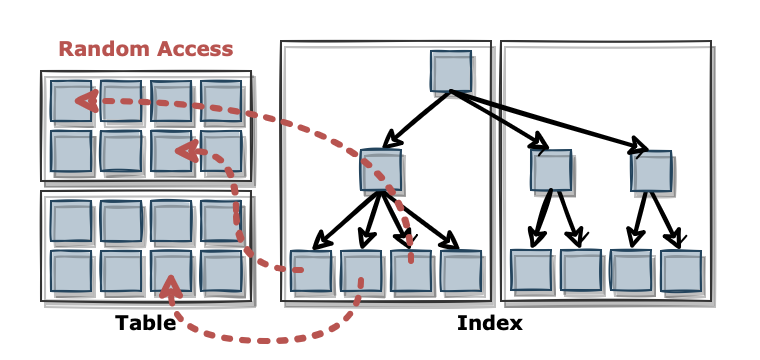
Index Range Scan 이란
랜덤 액세스와 Single Block I/O 방식으로 디스크 블록을 읽는다.
캐시에서 블록을 못 찾으면, '레코드 하나를 읽기 위해 매번 잠을 자는 I/O 메커니즘이다.
따라서 많은 데이터를 읽을 때는 Table Full Scan 보다 불리하다. 열심히 일해야 할 프로세스가 대기 큐에 들어가서 잠을 자버려서 스캔 성능이 안나온다.
게다가 이 방식은 읽었던 블록을 반복해서 읽는 비효율이 있다. 한 블록에 평균 500개의 레코드가 있다면 같은 블록을 최대 500번 읽을 수 있다는 것이다. 인덱스를 이용해서 '전체 레코드' 500개를 액세스한다면 각 블록을 단 한번만 읽는 table full scan 보다 훨씬 성능이 떨어진다.
따라서, 읽을 데이터가 일정량을 넘으면 인덱스보다 Table Full scan 이 유리하다.
추가) Index Fast Full Scan
말 그대로 Index Full Scan 보다 빠른 스캔 방식이다.
빠른 이유는? 논리적인 인덱스 트리 구조를 무시하고! 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔하기 때문이다. 그런데 인덱스 리프 노드가 갖는 연결리스트 구조를 무시하고 물리적 구조로 읽어나가기 때문에 정렬이 안된다. 그리고 쿼리에 사용한 컬럼이 모두 인덱스에 포함돼 있을 때만 사용할 수 있다는 것도 특징이다.
Index Range Scan 또는 Index Full Scan 과 달리 인덱스가 파티션 돼 잇지 않더라도 병렬 쿼리가 가능한 것도 주요 특징이다. 병렬 쿼리 시에는 Direct Path I/O 방식을 사용하기 때문에 I/O 속도가 빠르다.
인덱스 논리적 구조
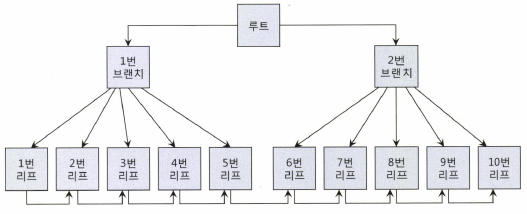
Index Full Scan 은 인덱스의 논리적 구조를 따라 루트 → 1번 브랜치 → 1번 리프 → 2 → 3 → 4 → ... → 10 번 순으로 블록을 스캔한다.
인덱스 물리적 구조
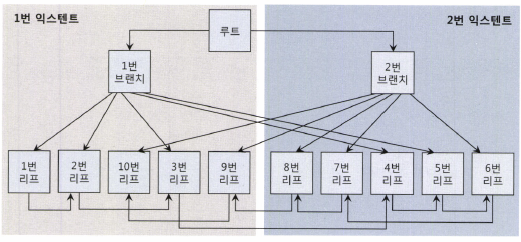
Index Fast Full Scan은 물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록들을 읽어들인다.
Multiblock I/O 방식으로 왼쪽 익스텐트에서 1번 리프 → 2번 리프 → 10번 리프 → 3번 리프 → 9번 리프 를 읽고, 그 다음 오른쪽 익스텐트에서 8번 리프 → 7번 리프 → 4번 리프 → 5번 리프 → 6번 리프 순서로 읽는다.
루트와 2개의 브랜치도 읽긴 하지만 필요 없어서 버린다.
비교
| Index Full Scan | Index Fast Full Scan |
| - 인덱스 구조를 따라 스캔 - 결과 집합 순서 보장 - Single Block I/O - 파티션 돼 있지 않다면 병렬스캔 불가 - 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능 | - 세그먼트 전체를 스캔 - 결과집합 순서 보장 안됨 - Multiblock I/O - 병렬 스캔 가능 - 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능 |
정리
Reference
- 조시형, 친절한 SQL 튜닝, 디비안, 2018-06-01
- 이미지 출처 데이터베이스 구조 - miintto.log
'Database > Oracle' 카테고리의 다른 글
| 오라클 인덱스(Index) 구조 - B*Tree (0) | 2023.11.16 |
|---|---|
| 계정 생성 (0) | 2023.04.04 |
| [PL/SQL] Cursor (0) | 2022.08.11 |
| Oracle RAC (0) | 2022.07.19 |
| Instance 구성 (0) | 2022.07.19 |



